����ʦ���û�ָ��
ϵͳҪ��
Ŀ¼
2. �߾�������ʶ����
��
��ת��
��
1.
�����߾��ȼ���ת��
1.1 ��ҵ���ȵ������߾��ȼ���ת������
1.2 �༭��ת�롢������ת�롢�ļ�/��ҳ/Ŀ¼/��վת��
1.2.1 �༭��ת��
1.2.2 ������ת��
1.2.3 �ļ�/��ҳ/Ŀ¼/��վת��
1.2.4 �����ļ�/�ļ��м�ת��
1.3 ������á���ʦ��ʵ�� Word��Excel��PowerPoint��Access��Trados
TM...�ȶ���������ʽ�ĵ��ļ�ת����
1.4 ʵʱ/��̬��ת���������нӿڡ�����ת��
1.5 Unicode ���ת�� - �� Unicode/Unicode BE �� GBK/Big5/UTF-8 ֮��ת��
1.6
���ܴʻ�����
1.7 ������á���ʦ��ʵ������Ʒ��ת��
1.8 ����֪ʶ���������ġ��������ġ�GBK��GB2312��Big5��UTF-8��Unicode �� Unicode BE
��
1.1
��ҵ���ȵ������߾��ȼ���ת������
��
���¹�����������ʵ�ָ�Ʒ�ʼ���ת�롣���ڣ��û��Ѿ��������á���ʦ�����ָ������ʵ������Ʒ�ʼ���ת�룬��һ����������ҵ����ˮƽ��
��
���¹�����Ͷ��������������ת������ľ��ȡ�ͨ�������ر���Ƶ����̼�ר�ó���� GBK �����GB2312 ����� Big5 �������������ˣ��ο��˶�����ر�����ͨ�����������ı���Դ����У�ԣ���ȷ��ת��ȷ�������������ǵ��ڲ����ԣ���ǰ�汾�ġ���ʦ���� GBK �����GB2312 ����� Big5 �����ת��ȷ�����ѷֱ�����ҵ����ˮƽ������Ʒ��������ں��ֿ⣬����ʦ������Ŀǰ���Ƚ��Ĵʻ������������ṩһϵ�о�������γɵĴʻ������⣬����Բ�ͬת�������ṩ������������ϵ���û�ͨ���ʻ��������������ɵ�Ϊָ��ת����������ר�ŵļ���ת�뷽�����ڴ��������£�ֻҪ�������䣬ת��Ʒ�ʿ��Դﵽ�û���ת������������������������������صĽ�һ��ϸ����ο�
1.6
���ܴʻ�������
��
Unicode �ַ��������� GBK �ַ���������Ŀǰ�ѳ�Ϊ������ȫ��ͳһ���뼯��Unicode
�ַ�������һЩ�ϳ��÷��Ų�δ������ GBK ���뼯�С��̶���ǰ����ʦ������ GB2312 �Ŀ�ܣ�ȫ����� GBK
����뼯����ת��֮���� 2.9 �����ʦ���ֳ�Խ�� GBK ת��ʱ�������� Unicode ����ת�������������Ƕ�ת����������˹ؼ��Ľ������ڣ�������
UTF-8��Unicode��Unicode BE ����֮����м����塢�ļ���Ŀ¼ת��ʱ�������ڲ�ʹ�õ���ȫ�µ� Unicode ת���������ת������������ʵ��
Unicode �ı�������ת����
��
����ʦ����ת�����澭���ر��Ż���ת���ٶ���ͬ����������ԽϿ졣��ʵ�ʲ����У�ת���ٶ��������õ������ܣ��Լ��õ��Ĵʻ��������еĴ������йء�
��
����Խ��ת�����棬����ʦ���ṩȫϵ�м���ת��������༭��ת�롢������ת�롢�ļ�/��ҳ/Ŀ¼/վ��ת�룬��Ϊ Word��Excel��PowerPoint��Access �� Trados TM �������ʽ�ĵ�������ת���ṩ��רҵָ��������ת�����߱�ʼ����һ��רҵƷ�ʡ�
��
1.2
�༭��ת�롢������ת�롢�ļ�/��ҳ/Ŀ¼/��վת��
��
�༭��ת����������ת�����ļ�/��ҳ/Ŀ¼/��վת���ֱ����ڶԱ༭���ͼ������е��ı����Լ��������ļ�����ҳ���γ������Ŀ¼����վ���з����רҵ��ת������Щ����֧�ּ��� GBK��Big5�����壩��UTF-8��Unicode �� Unicode
BE ���������֮���רҵ����ת��
��
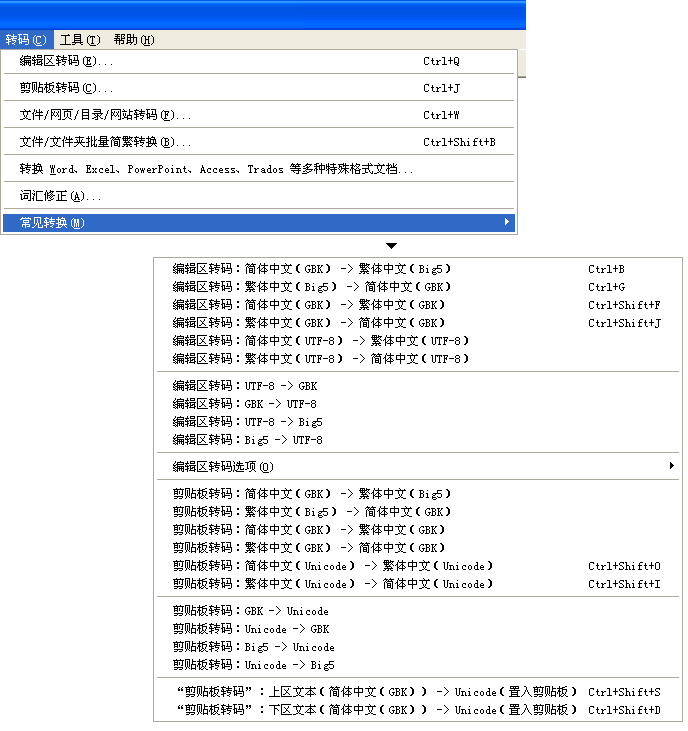
��
ͼ
UG-1-1 ȫ��ת�빦�ܾ����ڡ�ת�롱�Ӳ˵����ҵ����༭��ת�롢������ת�롢�ļ�/��ҳ/Ŀ¼/��վת�����������壬��ͨ����ݼ����ٴ�ת�����˵�����µġ�����ת���������˵����г�������ı༭���ͼ�����ת������������������ѡ�á�ͨ�������˵��еġ��༭��ת��ѡ���������ͨ���˵������������ťִ�б༭��ת��ʱ����������ϱ༭����ԭ�ı�����д���±༭�������ǽ��������á�����->��������Ĭ�����á�
��

��
ͼ
UG-1-2 �Ϲ������ϵı༭�� GBK<->Big5 ת����ļ�/��ҳ/Ŀ¼/��վ����ת�밴ť�����Ȧ�е�������ť�DZ༭����ת����GBK->Big5���ͱ༭����ת��Big5->GBK�����ұ�Ȧ�еİ�ť���ļ�/��ҳ/Ŀ¼/��վ����ת�밴ť��
��

��
ͼ
UG-1-3 �� 100 KB ���ϵ��ַ����м�����ת���༭��ת��ʱ�������Կ���һ��ת���������
��
1.2.1
�༭��ת��
��
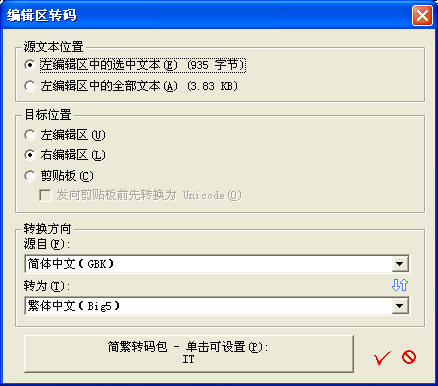
��
ͼ
UG-1-4 ʹ�á�ת�롱�˵��µġ��༭��ת�롱����ɴˡ��༭��ת�롱��塣����Դ�ı�λ�ö������ϱ༭�������Խ������������ı�ʱ���ſɴ���塣
��
�༭��ת����ϱ༭���е��ı����м�ת�롣�������á��༭��ת�롱������ת�룬���ṩ����ȫ��ת�����ѡ������ڼ��� GBK��Big5 �� UTF-8 �����������ϼ����ת�������⣬��Ҳ�������ö���ת��˵��ϵ�����������ϵİ�ťִ�м��ֳ����༭��ת�������
��
���ڱ༭��ת������ϱ༭������Դ�༭�����е��ı�����ת�������Խ������������ı�ʱ���ſ�ִ�б༭��ת�롣
��
1�����á��༭��ת�롱������ת��
��
ִ��
ִ�С�ת�롱�˵��µġ��༭��ת�롱����ɴ���塣��ݼ��� Ctrl+Q���������ͼ UG-1-4��
��
���ܼ�˵��
Դ�ı����ϱ༭���е�ѡ���ı������ϵ��༭���������ݱ�ѡ��ʱ�ſ��ã����ϱ༭���е�ȫ���ı���
Ŀ��λ�ã��ϱ༭�������Ƽ������±༭��������塣�����Ŀ��λ����Ϊ�ϱ༭����Դ�ı��������ǣ����Բ��Ƽ�ʹ������λ�á�������Ŀ��λ��Ϊ������ʱ����һ��ר�ŵĿ�ѡ��ɽ�ת�������תΪ Unicode������������塣
ת������Դ���Ŀ����ɷֱ�Ϊ
��
* �������ģ�GBK��
* �������ģ�UTF-8��
* �������ģ�Big5��
* �������ģ�GBK��
* �������ģ�UTF-8��
��
�е���һ�֡��������� 5*4=20 �ֱ༭��ת�뷽��ɹ�ѡ��
��
2�����ò˵��������ϵı༭��ת������ִ�г��ñ༭��ת�����
��
��ͼ UG-1-1����������ת��˵�����µĶ����˵���ִ�ж�����༭��ת����������⣬�Ϲ������ϵ� AA->U / A->U��G->B��B->G ���¹������ϵ� AA->U / A->U ��ť��Ҳ�DZ༭��ת������������ȥ��ͨ����ʾ�����˽ⰴť����Ĺ��ܡ������˵��еġ��༭��ת��ѡ�����Ϊ������->������������->������������ר����ͨ���˵��Ͱ�ťִ�еı༭��ת�롣
��
����ת�빦�ܿ�ʵ���ı��Ŀ��ӻ�ת�롣�������趨���ϱ༭���ڵ��ı���������ת�룬ת�����������ϱ༭������ʾ��Ҳ�����趨��ת������ʾ���±༭������������£���������ת������ʾ���±༭���У��������Է���ض��ռ��ת��Ч����Ҳ���Ա����ϱ༭���е�ԭ�ġ�
��
��ͼ UG-1-3����Ҫת���ַ������� 100 KB������ʦ��������һ��������ʵʱ��ʾת����ȡ�����ʦ����ת�����汾���ٶȺܿ죬���������Ҫת���ı��ַ����Ƚ϶࣬��ת��������༭����ʾ�������ܻỨһЩ�����ʱ�䡣
��
��

��
ͼ
UG-1-5
�༭��ת������༭�����ı���ʾ���Խ��Զ��������Ӷ�����ȷ��ʾת�����ԡ���ͼ�Ǹ�����Big5��ת��GBK�������ӡ�ת��������ϱ༭����ʾ���Ա�����Ϊ�������ģ�Big5�����±༭������ʾ���Ա������ɼ������ģ�GBK����
��
1.2.2
������ת��
��
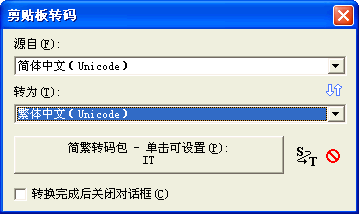
��
ͼ
UG-1-6 ʹ�á�ת�롱�˵��µġ�������ת�롱����ɴˡ�������ת�롱��塣ֻ�е������������ı�����ʱ���ſɴ���塣
��
������ת��Լ������е��ı����м�ת�롣�������á�������ת�롱������ת�룬���ṩ����ȫ��ת�����ѡ������ڼ��� GBK��Big5��UTF-8��Unicode��Unicode
BE �����������ϼ����ת�������⣬��Ҳ�������ö���ת��˵��ϵ�����������ϵİ�ťִ�м��ֳ���������ת�������
��
���ڼ�����ת����Լ������е��ı�����ת�������Խ��������������ı�ʱ���ſ�ִ�д���ת�롣
��
1�����á�������ת�롱������ת��
��
ִ��
ִ�С�ת�롱�˵��µġ�������ת�롱����ɴ���塣��ݼ��� Ctrl+J���������ͼ UG-1-6��
��
���ܼ�˵��
Դ���Ŀ����ɷֱ�Ϊ
��
* �������ģ�GBK��
* �������ģ�UTF-8��
* �������ģ�Unicode��
* �������ģ�Unicode
BE��
* �������ģ�Big5��
* �������ģ�GBK��
* �������ģ�UTF-8��
* �������ģ�Unicode��
* �������ģ�Unicode
BE��
��
�е���һ�֡��������� 9*8=72 �ּ�����ת�뷽��ɹ�ѡ��
��
2�����ò˵��������ϵļ�����ת������ִ�г��ü�����ת�����
��
��ͼ UG-1-1����������ת��˵�����µĶ����˵���ִ�ж����������ת����������⣬���¹������ϵ� G->U���� GBK->Unicode����U->G���� Unicode->GBK��B->U���� Big5->Unicode���� U->B���� Unicode->Big5����ťҲ�Ǽ�����ת�������ij�༭���ı���Ϊ GBK ʱ��U->G �� G->U ��ť���ã���ij�༭���ı���Ϊ Big5 ʱ��U->B �� B->U ��ť���á�
��
��ͼ UG-1-3���ͱ༭��ת��һ������Ҫת���ַ������� 100 KB������ʦ��������һ��������ʵʱ��ʾת����ȡ�
��
1.2.3
�ļ�/��ҳ/Ŀ¼/��վת��
��

��
ͼ
UG-1-7 ���ļ�/��ҳ/Ŀ¼/��վת�롱�Ի���
��

��
ͼ
UG-1-8
���ڽ���վ��ת�롣����վ��ת��ʱ����������⽫��ʵʱ��ʾת��״̬���������һ��������վ����ת��ʱ���Ϳ���һ��������������һ�߿ɴ��������Ͽ���ת��״̬����������ֹת�룬�ɵ���ת��Ի����а�Ȧ��ʾ��ť��
��
�ļ�/��ҳת���Ŀ¼/��վת��ʹ��ͬһ���Ի��������Դ�ת��˵����ҵ����ļ�/��ҳ/Ŀ¼/��վת�롱���Ҳ����ͨ���Ϲ������ϵġ��ļ�/��ҳ/Ŀ¼/��վ����ת�롱��ť��ͼ UG-1-2 �ұ�Ȧ�еİ�ť��������Ի���ѡ������ļ�/��ҳת��ʱ���Ի����е�ѡ�����ʾ��Ϣ������ļ�/��ҳת���ѡ�����ʾ��Ϣ��ѡ�����Ŀ¼/��վת��ʱ���Ի����е�ѡ�����ʾ��Ϣ��Ϊ���Ŀ¼/��վת���ѡ�����ʾ��Ϣ��������ѡ������ת�뷽ʽ��Դ���Ŀ����ɷֱ�Ϊ
��
* �������ģ�GBK��
* �������ģ�UTF-8��
* �������ģ�Unicode��
* �������ģ�Unicode
BE��
* �������ģ�Big5��
* �������ģ�GBK��
* �������ģ�UTF-8��
* �������ģ�Unicode��
* �������ģ�Unicode
BE��
��
�е���һ�֡��������� 9*8=72 ��ת�뷽��ɹ�ѡ��
��
1.
�ļ�/��ҳת��
��
��������ת��������Ϊ��һ���ļ�/��ҳ��ʱ����������������ļ�/��ҳת���������Ϣ��
��
����ѡ��ת���������Ϊ���ļ�/��ҳ����Ŀ���ļ�������Դ�ļ���ͬ������ѡ����Ա�������Դ�ļ����ᱻ�����и��ǡ������ѡ��ת���������Ϊ���ļ�/��ҳ����ת�������д��Դ�ļ���
��
���ת�����ļ�����ҳ����������ҳ���Ա�ǣ�ת��ʱҲ���Զ������Ա�ǽ���ת����ת�������ҳ���Զ���ָ��������ȷ��ʾ��
��
�����Ե����ұߵ��ļ�ͼ��鿴Դ�ļ���ת�������
��
2.
Ŀ¼/��վת��
��
������ת��������Ϊ��һ��Ŀ¼/��վ��ʱ���Ի�����ʾ���Ŀ¼/��վת���ѡ�����ʾ��Ϣ��
��
����ѡ��ת���������Ϊ��վ�㡱��Ŀ��վ�����Ϊһ�������ڵĴ���Ŀ¼����һ��û�����ݵĿ�Ŀ¼����������ȷ�������������ƻ�һ������Ŀ¼�е����ݡ�
��
����Ŀ¼/��վת��ʱ������ʦ�����Զ�ʶ��һ���ļ��Ƿ����ı��ļ���������ı��ļ������ת�������������ת����������ת���������Ϊ��վ��Ļ�������ѡ���á���ʦ��������ת���ķ��ı��ļ�ͬʱ���Ƶ���Ŀ¼�µ���Ӧλ�á���Щ���ı��ļ�����Ҳ����վ�ı�Ҫ��ɲ��֣���ͼƬ��ѹ���ļ���������ҳ���ṩ�����ӵ���Դ��
��
��վ����ȫ����ҳ�ļ������Ա������Խ����Զ���ΪĿ���롣��ͼ UG-1-7 �н��е�վ����壨GBK��ת���壨UTF-8����ת����ɺ�"F:\lanlib1\UTF-8"Ŀ¼����ҳ�ļ������Ա������Խ��Զ���ԭ���ļ������ģ�GB2312����Ϊ UTF-8��
��
����·���༭���Ҳ��Ŀ¼ͼ�꣬���Բ鿴Դվ���ת�������ת����ɺ�ɲ鿴����Ŀ¼�ṹ��
��
1.2.4 �����ļ�/�ļ��м�ת��
��
�˹����൱���ɶ��ת��/����������ɵ�������ת���꣬ÿ�����֮Ϊһ��������ת��������һ���Զ�һ���ļ����ļ��н�������ת����������ת�����̵�����һ����ಽ�е���ָ��ת�������ɶ�ÿһ���ļ����ļ���ת����������Դ/Ŀ��·����ת������ת��ѡ��˹��ܼ���ط����˾�����Ҫ�ֱ𰴲�ͬ���ý��ж����ļ����ļ��м�ת�����û���
* �˹��ܿ��ڡ�ת�롱�˵����ҵ�����ݼ�Ϊ Ctrl+Shift+B��
*
ÿ���꣨������ת���������������ԣ����ơ����ߡ��汾��˵����·��...�ȣ��������б��������С�����ת����������ת���ļ�/�ļ��С��͡��ļ�ϵͳ�������ܡ��������������ͨ��ѡ��ָ�������н�����ָ�ԭ���ļ�ת�������á�
*
�������ڡ�ת���ļ�/�ļ��С������н�һ��ָ��ת���Ķ������ļ������ļ��С���ת������Ϊ�ļ��У����Բ���ָ���ɸ��������ļ��У���ѡ�������ڰ��а�������������ʱ���������С�
*
���������б�����������������������ӡ�ɾ�����ġ����С����ơ�ճ�������ơ��������������/ȡ������ġ�Ӧ�á�״̬����δӦ�ã���������Ա����������б��У�������ִ�У��������ӡ��༭����ֻ����������⣬���������֧�ֶ�ѡ����������
*
֧���ļ�/�ļ����Ϸţ�������һ���Խ�����ļ�/�ļ������������б��С�����ת�����ļ����Զ���������ת����������������ı��ļ����ļ��м��Զ������ļ����ļ��е�ԭ·��ת�������Ҳ�����ڱ༭��������ʱ��һ��ת�����ļ��������ı��ļ����ļ�������ﵽͬ��Ч�����˹���Ҫ��
Windows 2000��XP��2003������ʹ�� Windows Vista��7 ��֧�֣�ԭ���� Windows Vista��7 ������֧���ļ��Ϸš�
*
��������һ�����༭Դ�ļ�����ť�������ֱ�ӱ༭Դ�ļ���������Զ���ʾ���¡��˹��ܱ����������������ɡ���ϸ�������
*
���ܽ�����������ţ�����ʱ����ؼ��IJ��֡����п���������ʾ���������ֵij���Ҳ���Զ���Ӧ��������ѣ����ڴ���ʾ���û��鿴��������
* �����Խ���������İ�����Ϊ���ı��ļ���Ҳ������ʱ������ǰ����İ���
*
���ļ�ϵͳ�������ܡ��������ִ�г����½������С����ơ�ճ����������ݷ�ʽ��ɾ����������/�ƶ������Ե�����������������������Ҽ��û�ִ������ת��ʱ��һЩ�������ļ�ϵͳ�������Ե��Բ�������Ϥ����ͨ�û�����Ҫʹ����Щ���ܡ�
��
1.3 ������á���ʦ��ʵ�� Word��Excel��PowerPoint��Access��Trados
TM...�ȶ���������ʽ�ĵ��ļ�ת����
��
����ʦ��רע�� GBK��Big5��UTF-8��Unicode �ȹؼ������ʽ�ı����ļ���רҵƷ��ת��������ֱ�Ӳ��� Word��Excel��PowerPoint��Access��Trados
TM �������ļ���ʽ��������ʦ��Ҳ�����˼�ӣ����Ժܷ�������̣�ָ���û��ڡ���ʦ���İ�����ʵ����Щ�����ʽ�ļ���רҵƷ�������ת������Ϥ��Щ���̺�ȥ����ת������Ҫ����ʱ�䣬��ֻ�� 1 ���ӣ�����ʵ�ֶ��������ʽ�ļ���רҵƷ�������ת����
��
����ת���Ļ���ԭ��
��
1������Щ�����ʽ�ļ�����Ϊ XML���� UTF-8���ȡ���ʦ��ʶ��ĸ�ʽ������ʱҲ�Զ���������������������ĸ�ʽ��Ϣ����
2���ɡ���ʦ���Ե����� XML �ȿ�ʶ���ʽ����רҵƷ�ʼ�ת����
3�����б�Ҫ��ͨ�������滻�ȷ�ʽ����ת���������һ����������һ��������ʡ�ԣ���
4�������� 2��3 �����Ľ�����µ����������������Ϊָ����ʽ��
5�����б�Ҫ�����м��ڴ�������һ��������ʡ�ԣ���
��
��һ��ϸ��
��
���� Word��Excel��PowerPoint ��ת�����Լ������ʽ�ļ���ת����һ����˵��������� FAQ �еġ����ת�� Word��Excel��PowerPoint��Access...��������ʽ�ĵ�������
���� Access ��ת��������� FAQ �еġ���Ҫת��һ�� Access ���ݿ�����
���� Trados TM ��ת��������� FAQ �еġ�����һλ������Ա������һ�� Trados ��Ӣ����� TM �⣬��ת����Ӣ�뷱��⣬�������ʵ�֣�����
��
1.4 ʵʱ/��̬��ת���������нӿڡ�����ת��
��
ʵʱ/��̬��ת���������нӿ�
��
��Щ�������û�����վվ����ϲ�������в���������������ϣ������ʦ��
���ṩ��ͨ������������ʵʱ����̬���õļ�ת���ӿڣ�Ϊ�ˣ����ǿ����������й��ܡ�������ͨ�������й���ʵʱ���á���ʦ�������ļ���Ŀ¼��ת���������й��ܽ��ڡ�����ʦ���������ṩ�������汾����ʦ�����ṩ�˹��ܡ����������й��ܵľ���ϸ����ο���
��
��¼ 3. ������ָ�ϣ�����ʦ������ר�����ܣ�
��
����ת��
��
1����Ŀ¼ת�����桰����ת����
��
��Щ����������û�ϣ���������ṩ����ת�빦�ܣ�ԭ������Щ�ļ���Ҫת��������Щ�ļ�����Ҫת����һ����������ת��̫�鷳��ʵ������Щ�û�֮�����������Ҫ����������Ϊ��Ŀ¼ת
����ǿ�����˽ⲻ�����¡�
��
��ע�⣬�����ṩ��Ŀ¼ת�����ܿ��Զ�Ŀ¼�����и�����Ŀ¼����ת��������ת��ʱ���Զ�ʶ���ı��ļ�����ת����ֻת���ı��ļ���������ѡ��
Word��ͼƬ��ѹ���ļ��ȷ��ı��ļ����Ƶ�Ŀ��Ŀ¼�µ���ͬλ�á��������������һ��������վ��һ����վһ�����һ��Ŀ¼����Ҫת���ɷ��壬����һ��������վ��Ҫת���ɼ��壬ֻ��Ҫ�����Ŀ¼ʵʩĿ¼ת�����ɣ�ת����ɺ��������ӹ�ϵ��������ȷ�����������ı��ļ�Ҳֱ�Ӹ��Ƶ����λ�á���Ȼһ����ʲô���㶨�ˣ���Ҫ������ת������ʲô��Ҫ��
��
������ж���ļ������ļ����µ�������Ҫת����ֻ��Ҫ�����Ǹ��Ƶ�һ��Ŀ¼�£�Ȼ������Ŀ¼����Ŀ¼ת����Ҳ����һ�ξͽ���ˡ�
��
���Դ������ͨ�û�������Ҫ�ر������ת�����ܣ����е�Ŀ¼ת�����ܾ��Ѿ��㹻�����ˡ�
��
2���������нӿ�ʵ������ת��
��
��Щ�û�����ijЩ�����ԭ������Ҫר�ŵġ�����ת�������ܣ�������Щ�û�����ʦ�����档���������ñ���֧�ֵ������й���ʵ������ת������ֻ��Ҫ���������ṩ�������������ļ����������ӵ�����������������ļ������ص�ַ�����������������ļ��е�Դ�ļ�+Ŀ���ļ���ԴĿ¼+Ŀ��Ŀ¼��·��������ָ�����ļ���Ŀ¼·�����ɡ�ÿ������Ϊһ�У�һ���������ļ��ɰ���������С�������Ϊÿ��ת�����ò�ͬת������������ʵʱ����ת������
��
��һ��ϸ����ο���
��
��¼ 3. ������ָ�ϣ�����ʦ������ר�����ܣ�
��
1.5 Unicode ���ת�� - �� Unicode/Unicode
BE �� GBK/Big5/UTF-8 ֮��ת��
������� NT/2000/XP/2003/Vista ��ϵͳ�´���ҳ�ϸ����ı������� Windows XP ���� Notepad �༭�ı������������������� Unicode ��ʽ�����ݡ���ʱ��������ϵͳ��ճ������ʦ��������ͳ�����༭���ϵ��ı������????��������Ϊ���������IJ��� GBK �� Big5������ Unicode ��ʽ���ı���
��
������ֱ�Ӷ� Unicode ��ʽ���ı����м�ת��������ʹ�á���ʦ��������ת�빦�ܣ�����ѡ����壨Unicode��->���壨Unicode�����壨Unicode��->���壨Unicode����
��
�������Ҫ�༭�������е� Unicode �ı������������¹������е� U->G �� U->B ��ť����תΪ GBK �� Big5 ���룬������༭���н��б༭���༭��ɺ����ù������ϵ� A->U �� AA->U ��ť���༭���е�ȫ����ѡ���ı����Ƶ��������У����� G->U �� B->U ��ť����ת�� Unicode ��ʽ��������ij�༭���е����Ա���Ϊ GBK���� U->G �� G->U ���ã������Ա���Ϊ Big5���� U->B �� B->U ��ť���á��������� U->G / G->U �� U->B / B->U ֮������л�����ֻ���л��ñ༭�������Ա��뼴�ɡ�
��
�������Ҫ����Ҳ�������ü�����ת�빦���� Unicode/Unicode BE �� GBK��Big5��UTF-8 ֮��ת�롣
��
1.6 ���ܴʻ�����
��
����ʦ���ṩ���ܴʻ��������ܣ����Խ�һ�����ת�뾫�ȡ�
��
�����ʻ�������ת��Ч��Ҫ��û�о����ʻ�������ת��Ч���õöࡣ
1.
���ּ������硰�ơ�-���ƶȡ��������ơ����ڷ��������и���ʹ�û�����ͬ���ɽ���ӳ����ͬ�ķ����֣��硰�ƶ��������}�u����
�ӷ��������ת��ʱҲʱ��������������֡��緱���еġ�����-���㿴�������������������ڼ���������������㿴������������������
2.
�ִ������е�һЩ�����ʺ��ճ��÷����ڼ�����Ҳ����������ͬ����Ӣ�ĵ� modem�������õġ�è�������ڼ��������е���ʽ�����ǡ����ƽ���������ڷ��������У����֮Ϊ�������C����
ͨ���ʻ�������������ʵ������ת��Ҫ��ʵ�ʵĴʻ�����⣬��Ҳ���Ժ������ôʻ����������ں��ʵ�ʱ�������ĵ��κ����ݽ��е�����
��
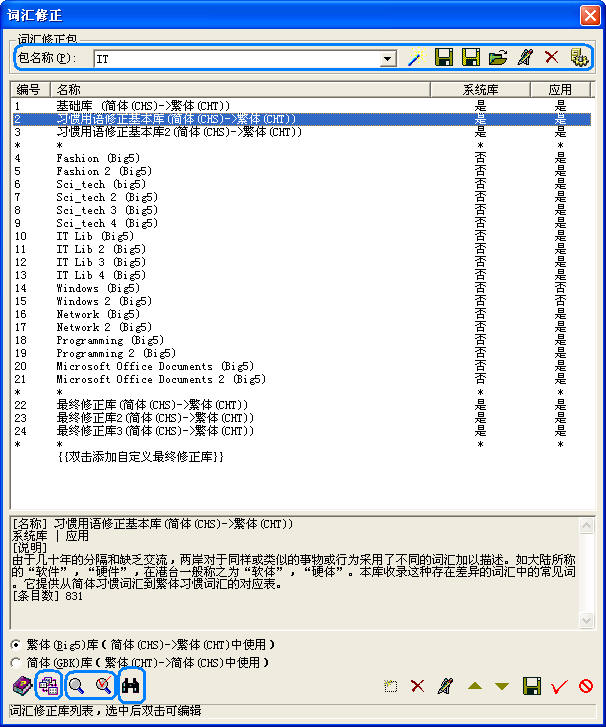
��
ͼ
UG-1-9
������ת�롱�Ӳ˵��¡��ʻ�������������Դʻ����������档���˵��б��Ͱ�ť������ڴʻ��������Ĺ��������ӡ�ɾ�����༭��Ӧ�õȣ������½ǰ�����ť�Ե� 4 ����ť������ʵ�ִʻ���������ںϡ���Ч�Լ��/�����Զ�����������һ�������п�������ָ���ʻ㡣���½ǵİ�ť������ڴʻ�������Ĺ�����������������κ�һ�������ʱ����˵�״̬���п�����ʾ���˵����
��

��
ͼ
UG-1-10
�༭�ʻ������⡣�������ڴ˱༭��������⡣ֻ�е���ѡ��Ӧ�ñ��⡱ʱ��ת��ʱ�Ż��������⡣����˴ʿ������뵱ǰ����ϵͳ���벻һ��ʱ����������ȷ��ʾ����ѡ����Ŀ�������ʿ������б��ϵı༭������ȷ��ʾ�������������ϲ������һ����һ���ʽ��б༭�������Ե����б��Ҳ�Ȧ�е��ļ�ͼ�꣬�¿�һ������ʦ����������ڵ����ݽ���ȫ�ı༭��ȫ�ı༭Ӧ�ڱ��Ի����ʱ���У�ȫ�ı༭�����������Ľ������ʦ������ʾ������ȫ�ı༭�Ľ���滻��ǰ�⡣��ͼ UG-5-11 ��ʾһ������Ҳ�����ڴ˶Ի����жԽ�����Ч�Լ�飬ֻ����������Ե�ǰ����/�������İ�ť�ɰ��������ִ���ʱ�Զ���������ָ������������
��
�ʻ������������ -
һ�鷱������ڼ�ת��ʱ��������һ���������ڷ�ת��ʱ��������
��
����ʦ����װ��Ϊÿ����ṩ
6 ��ϵͳ�⣬���Ӽ����Զ���רҵ�⡣
��
������ɾ��ϵͳ�⣬�����Ա༭���ǡ����������������һ�е�ר�ң���������Ҫ��
ϵͳ�⡣��������Զ����������Ҫ�����Դ����Լ���������������ά��һ�����Զ��������⣬������ο���¼ 2. �ʻ��������涨�ƹ���������Ϊϵͳ���һЩ�����Զ����ļ�Ҫ˵����
��
���¹����Ҷԡ���ʦ����ת������ĸĽ�һֱ�ڳ������ϵؽ��У�����Ϊ���ṩ���õ�ת��Ч������ʱ����ϵͳ����Զ���⣬ˡ������֪ͨ��
��
ϵͳ�⣺
��������������Բ�ͬ�ᄈ�µĵ��ֽ��������������� GBK �� Big5 �����ʻ������ĺ��ġ�������Լ����һ�Զ���������������
ϰ���������������������ڼ�ʮ��ķָ���ȱ��������������һЩ��ͬ�����Ƶ��������Ϊ�����˲�ͬ�Ĵʻ�������������½���Ƶġ�����������Ӳ�������ڸ�̨һ���֮Ϊ�����塱����Ӳ�塱��������¼���ִ��ڲ���Ĵʻ��еij����ʡ����ṩ����䲻ͬϰ������Ķ�Ӧ����
ϰ���������������� 2����ϰ���û�����������δ�������Ĵʻ���в���������
������������ͬʱʹ�ö����ʱ�������Ͽ��ܴ��ڼ��������벻�������������������ijһ����һ���������ʣ�������һ����������ǰ�Ѿ�����һ���⣬��ǰ���һ�����滻�ˣ����������ֱ��������Ĵʻ������е�ijһ���滻���滻��һ���֣���ʹ��������Ҫ��δ����ȷʵ�֡���ѱ�����ڿ��б���������������������Ŀ�����㷢�ֵ��������������������������
���������� 2��������������δ�������Ĵʻ���в���������
���������� 3�������������� 2 δ�������Ĵʻ���в���������
��
�Զ���⣺
IT �����ṩ IT ��ҵרҵ�ʻ��������
IT2-4 ������ IT ��δ�������Ĵʽ��в���������
Windows ������ Microsoft Windows �����еĴʽ���������
Windows2 ������ Windows ��δ�������Ĵʽ��в���������
Network ������������صĴʽ���������
Network2 ������ Network ��δ�������Ĵʽ��в���������
��
�Զ������������⣺
HongKong ������۵��������û�������ϰ����̨�����в�ͬ�������������û���ϰ���ṩ����������
��
�û���Ҫע���һ���ǣ��ʻ��������Ӧ��˳���ǰ��� UG-5-10 ����ʾ��������˳��Ӧ������������ijһ����������ʲô���⣬��������������Ŀ��н��и�����
��
���ڴʻ������Ľ�һ����Ϣ����ο���¼ 2. �ʻ��������涨�ƹ�����
��
1.7
������á���ʦ��ʵ������Ʒ��ת��
ͨ���������ð��������ܣ���������ʵ����������������ļ���ת�롣
��
һ���Խ���
��
��������Ϥ����ʦ�����ṩ�Ĵʻ����������ʻ��������б��������������п�������������Ϊ�Լ�����Ŀʵ�ָ�Ʒ��ת�롣
����һ������£����鲻Ҫ��ϵͳ��������ṩ�����������⡣������Ҫ�����Զ������������������������Զ������տ��У���������ʦ�����������������Ŀⲻ���ܵ�Ӱ�죬��������ά����
��
��ͨת������
��
������ͨ��ת��������Ӧ�á�Ĭ�Ͽ⡱�������� IT ��ص�ת��������Ӧ�� IT �⡣���ɶԴ����ת������ʵ��רҵƷ��ת�롣
��
רҵת������
��
ʵ������Ʒ��ת��Ĺؼ��������㣺
1��Ϊÿһ����Ҫ��ת�������ر���һ��ר�������������ô˰�����Ϊ�����������Ŀ�ѡ����������ñ���������ͳһ����������������������ҪΪ���������ת��ʱ��ֻ��Ӧ�ô˰�����ʵ��רҵƷ�ʵ�ת�롣
2���ڴ˰��ڣ������������Ϊ GBK �� Big5 ת������ֱ����� 1-2 ���Զ������������⡣
��
�������飺
3����Ϥ���������á���ʦ������ʦ����װ�����ṩ��ϵ�������⣺
a)
�˽���Щ�⣨�� GBK �� Big5 ���飬ÿ����� 6 ��ϵͳ�⣬���������Զ���⣬�����������������⣩����ʲô�ġ�
b)
һ������£���Ӧ��ȫ�� 6 ��ϵͳ�⡣Ĭ����������Ƕ�����ΪӦ�ã���Ҫ����ص�����
c)
�����Ҫ�� IT ���������ת�룬��Ӧ�ü��� IT ��ͷ��� IT �⡣IT ��ĵĴʻ��������ϸ���У����ԽϺõض� IT ���ļ��������������ת��Ķ����� IT �����ף�û�б�ҪӦ�� IT ��⡣
d)
��װ���л��м����Զ������������⣬������Ҫ��Ҳ��ѡ�á�
4���������������Զ������������⣺
a)
�����ڴ˴����Ϊ���������ر����������ʶԡ����һ������δ�ܴﵽĿ�꣬�����ڶ������н��в���������
b)
�����Զ����ִ��ԶԼ���վ���еIJ�ͬ���ӽ����������������е�����������"...\gb2312\abc.htm"�������˷����б��"...\big5\abc.htm"���������������Զ����������м�һ��"\gb2312\"->"\big5\"����������ת�������ֱ�Ӷ�������ģ���������ת����������ֹ�������
��
���ڴʻ������Ľ�һ����Ϣ����ο���¼ 2. �ʻ��������涨�ƹ�����
��
1.8 ����֪ʶ���������ġ��������ġ�GBK��GB2312��Big5��UTF-8��Unicode �� Unicode BE
��
�������ĺͷ�������
��
�� 20 �����ϰ�Ҷ����ʱ�Ĺ��������������ǹ�Ҫ�����֣��ú��ֵ�ѧϰ����д�����ף������ڹ���������ռ���������ʱ�ֲ��ȣ���һ�ƻ�δ������ʵʩ��
��
1949 ���Ժ�������������ȶ����ڴ�½���л�����������֯��ר��ίԱ�ᣬ�� 50 ����� 70 ����ڼ��������˺��ֵļ���������Ҫ�Ǹ�Ƶ�֣��ּ��ֻ�ƫ�Զ��ǽ������������/ƫ�Ժϲ�Ϊ����һ���ϼģ��������ĺ���/ƫ�ԣ�Ҳ�����ڹź���ܶ����Բ��飩���������ݣ�ƾ������ĺ��ֻ�ƫ��ֻռ�����еĺ���һ���֡�����̨�������һֱδ���к��ּ������Ӵ˾����˼��ֵ�����
��
���ڽ��к��ּ�ʱ�����Ὣ�����������������຺�ֺϲ�Ϊһ�����֣����õĺ���һ����д��Լ�Щ��������������ڼ����ֺͷ����ֵĶ�Ӧ��ϵ�У������ж��һ��Ĺ�ϵ�����⣬���������� 1949 ����������Ļ��ĸ��ң��� 1949 �������������´��У����൱�����ڼ��������Բ�ͬ��ʽ���������Ǽ����ĵ���һ��Ҫ����
��
���ڣ��й���½���¼��º��������Ƕ����ü���������Ϊ�ٷ����ļ����ռ�����̨�塢��ۡ���������÷������ġ�����������/�����ĺ��⻪���У���һ�������÷����ֽ϶࣬�������������Dz��ٽ������Ӵ�½�����ȥ�Ļ��ˣ�Ҳ�кܶ��ü������ĵġ������������ʮ������Ƶ���Ļ�����������������û�����ͬʱ���ϼ����ģ�����д���Ķ�ϰ���ϵIJ��첢�������Ըı䡣���ڼ����������������õ���Ҫ���й���½�����ڷ����������������õ���Ҫ��̨�塣���⣬����ڷ������ĵ�ʹ��ϰ����Ҳ��һ���Լ����ص㣬����Ӱ������С��̨�己���Ӱ�졣�����������������̨�徭������Ϊ�������ģ���ʾ����δ���������ǡ�����ԭ�桱�����ġ�
��
GBK/GB2312/Big5
��
������ַ������� 20 ����ĩ�� 21 ���ͳ������˴ӵ��ֽڣ��� ANSI ���룩��˫�ֽڣ�Unicode�������ת�䡣Windows
9x ��ǰ�� MS ����ϵͳ����Ҫ���õ��ֽڣ�ANSI�����뱣�桢���䡢�����ļ����������ݣ���һ���ֽڵij���Ϊ������ 8 λ������ 2 �� 8 �η����ܼ� 256 �ֻ����ַ��������ڵ� Windows
NT �ͺ����� Windows 2000 �Ժ�IJ���ϵͳ����˫�ֽ�Ϊ�ںˡ��ڵ��ֽڵļ�������ϵͳ�У������� GBK �����ʾ�����ڵ��ֽڵķ�������ϵͳ�У������� Big5 �����ʾ���������ֱ��ɲ�ͬ�˱ඩ�ı��룬�֮��û��ʲôֱ�ӹ�ϵ��
��
�ڵ��ֽ�ϵͳ�У�һ������������ֵΪ 1-255 �� ANSI �ַ���ʾ���ú����������� ANSI �ַ���ʾ���������ַ���������ֵı��롣GBK ����ı����й���½�ģ�������
Լ 2.2 ���֣����мȰ������������֣�Ҳ�����˻��������ķ��������֣����� GBK ʵ������һ�������ĵĺϼ���Big5 ������̨���ģ�����Լ 1.3 �����ģ�ֻ��¼�����������е��֣��ܶ�ֻ�����ڼ��������еļ���δ�� Big5 �������¼��
��
GB2312 ����˵�� GBK ��ǰ��������һ�� 6000 ���ֵļ������ĸ�Ƶ�ַ�����������һ����Χ�ڱ����ù�����һƪ�ճ��ļ������������У��ڲ����ظ�������£��������� 98%-99.5% �ĺ������� GB2312 �ַ����������������������ӣ��ܻ���һЩ������ GB2312 �ַ����ĺ��ֳ��֣������ھ������ϵͳ�У������ѱ����ָ�ȫ�� GBK �ַ���ȫ��ȡ���ˡ�GBK �ַ�����û�иı� GB2312 �г��ֵĺ��ֵı��룬ֻ�����ⲹ����¼�˴����������ֺͷ��š�GBK �� GB2312 ��������Ҫ���������棺��1��ȫ����¼�� Big5 �ַ����еĺ��֣���2��������¼��һЩ����ƫ�人�֣���3��������¼��һЩ�����š��ɴ˿ɼ���GBK �ַ���������Ҳȫ����� GB2312 �ַ�����������һԭ��Ҳ��Ҳ�� GB2312 �ȳ��֣�����Ϊ����ԭ�������������ڸ��ּ���������д������� GB2312 �����ƣ������ڳ��� GB2312 �ĵط���ʵ���������ַ��������Ѿ���һɫ������ GBK �ַ�����GB2312 ֻ�������˹�ȥ�����ơ�
��
Windows NT �� 2000 �Ժ��˫�ֽ�ϵͳ����֧��˫�ֽ��ļ�/���ݸ�ʽ��Ҳ����֧�ֵ��ֽ����ݡ��� 2000 �Ժ�ļ�������ϵͳ�У����ݾ���Ҳ�����Ե��ֽڵ� GBK ���뱣�棬����������ϵͳ�е�����Ҳ���������Ե��ֽڵ� Big5 ���뱣�档
��
Unicode/Unicode BE/UTF-8
��
Windows 2000 �Ժ��˫�ֽ� Windows ����ϵͳ������ Unicode ���롣Unicode ��һ��˫�ֽڣ���˵���ַ������룬һ�� Unicode �ַ���ԭ�����ֽ��ַ��������ַ���ô�������� 256*256=65536 �� Unicode �ַ������� Unicode �����ϴ������ƶ�ʱҲ�����˸�������ר���������飬Unicode �������ƶ����ʱ����¼�������������Ե������ַ�����ȻҲ�����˼������ĺͷ��������е������ַ�����������������������������Ը��ָ����ַ��ĺϼ������һ������ͬʱ�����ڼ������ĺͷ��������У����һ�����ú����ڼ���������û�б����ͻ������������������� GBK �� Big5 �о��в�ͬ�ı��룬���� Unicode ����ֻ��һ�����롣ʵ�������� GBK �����˼������� Big5 �ַ���Unicode �����Dz��� GBK ��¼�����ַ��ġ�
��
Unicode BE �� Unicode ����һ�ֱ�����ʽ����˵��һ�� Unicode
BE �ַ����ǰ����Ӧ�� Unicode �ַ���ǰһ��ͺ�һ�뻻��λ��������װ�γɵġ�
��
���ںܶ� Unicode �ַ����� ANSI ϵͳʶ�𣨱��磬ֵΪ 0 �� ANSI �ַ��� ANSI ϵͳ���ļ����ַ����ж���ʾ�ս�������� 0 ֵ���ܳ������ļ����ı����ݿ���м䣬�������һ�� Unicode ���ַ��ش��е�Ͽ�������� ANSI �ַ����ͻ����ܶ� X+0 �� 0+X �������������ֺܶ�Ϸ��� 0 �ַ��������Բ������� Unicode �ַ����Լ�ֱ��ǰ�����Ϊ���� ANSI �����ַ���UTF-8 Ӧ�˶����������� Unicode ��Ӧ�ļ��� ANSI ���ļ�/�ı�������ʽ��Unicode ת��Ϊ UTF-8 ʱ��ͨ��һ������һ��˫�ֽ� Unicode �ַ������ 1 ���� 2 ���� 3 �����ֽ��ַ��������Ϳ��Խ� Unicode ����������ȱ�ر���Ϊ���� ANSI �ĵ��ֽڱ������ݡ�
��
���� UTF-8 �ı��ʾ��� Unicode ���룬��������ͬʱ���ݵ��ֽں�˫�ֽ�ϵͳ��UTF-8 ��˫�ֽ�ʱ������Ҫ���ļ������ʽ��
|