STGuru User's Guide
8.
Changing the Layout for STGuru with the Help of Profile Management Contents A.1
Accelerator Keys
9. Tools
9.1 Character Count, Word Count, Paragraph Count and Line Count for Text, File and Folder
1)
Counting text in edit area
2) File/Folder Character/Word Counts
3) Comparison between STGuru and MS
Word on characters/word counts
9.2
Character Occurrences
9.3
Text Difference Check
9.4 Line Sorting
9.5
Redundant Line Management
9.6
Chinese-English Glossary Management - Merge, Split, Swap...
9.7 Chinese Characters to Decimal/Hexadecimal Unicode Codes
9.8 Page Cleaning
9.9 Term Management System
9.1 Character Count, Word Count, Paragraph Count and Line Count
for Text, File and Folder
1)
Counting text in edit area
You can click the "Word Count" command from under the
Tools menu
to count characters and words in the current edit area. If the currently active
edit area is the upper area, the text in the upper area will be counted,
otherwise, the text in the lower area will be counted. If some text in the
current edit area is selected, STGuru will only count the selected text.
STGuru's statistics include:
1) File information: file path, file times (created, modified,
accessed), key file attributes (read-only, hidden, archive, system);
2) Characters, words, paragraphs and lines: characters (all/ANSI = file/text
size), characters (all/supporting double-byte characters), characters (no spaces), characters (with spaces),
words (all), words (single-byte characters), words (double-byte characters),
paragraphs (all non-blank paragraphs) and lines (all paragraphs, including blank
lines).
When word counting is complete, you can click the "Text Report"
button at the right bottom of the dialog box to read a statistics report
in pure text.
2)
File/Folder Character/Word Counts
You can find this function from the Tools menu.
When you click this command, a dialog box for
file/folder counting will pop up. All recently counted files and folders
will be displayed in the path list. If a path you selected or
entered into the path edit box has been counted recently, its statistics will be
displayed below automatically. The software keeps statistical information for
recently counted paths. You can set the maximum number of paths in the path list
and the maximum days within which statistics will be kept in the Options dialog
box.
If the path you choose to count is a file, the file will be
counted. If you choose to count a folder, all text files in this folder
(including those in all levels of its subfolders) will be counted. STGuru will
detect whether a file is a text file, and based on which, it counts text files
and ignores non-text files.
The report of statistics as the result of the counting includes
the language and code of each text file as well as its characters (all/ANSI =
file/text size), characters (all/supporting double-byte characters), characters
(no spaces), characters (with spaces),
words (all), words (single-byte characters), words (double-byte characters),
paragraphs (all non-blank paragraphs) and lines (all paragraphs, including blank lines) for each text file and, at last, their totals.
If a file is detected to be in Simplified Chinese or English, the statistics will be
the same as those counted by Simplified Chinese version of MS Word, while if a
file is in Traditional Chinese, the statistics will be the same as
those counted by Traditional Chinese version of MS Word. If the product fails to
detect the code (such as when the file is in Traditional Chinese, but in the
code GBK, or when different codes exist in the same file, sometimes the product
may have trouble detecting the code), the file will be counted as if it is in
Simplified Chinese (GBK).
If the files you need to count are dispersed in different
locations of the hard disk, you can copy them to one folder before counting.
3)
Comparison between STGuru and MS Word on characters/word counts
| Item |
STGuru |
MS
Word |
Notes |
|
Characters (all/ANSI = file/text size)
Characters (all/supporting double-byte characters)
|
Available |
N/A |
|
|
Characters (no spaces)
Characters (with spaces)
Words (all)
Words (single-byte characters)
Words (double-byte characters) |
Available
(Same to each other) |
STGuru's statistics on these parameters are the same as those by a proper language version of MS Word. If the language of the current edit area is Simplified Chinese (GBK), the statistics are the same as those by a Simplified Chinese version of MS Word, while if the language of the current edit area is Traditional Chinese (Big5), the statistics are the same as those by a Traditional Chinese version of MS Word.
|
|
Paragraphs |
Available
(Same to each other) |
"Paragraphs" means the number of
paragraphs. It does not count blank lines (a blank line is a line
that has no characters, or only has blank spaces). |
|
Lines |
The number of lines counted by STGuru is the number of all
paragraphs, including blank lines.
The
difference between Paragraphs and Lines by STGuru is that Paragraphs
does not count blank lines (a line with only blank space(s) is also a decided by STGuru, as well as Word, as a blank line),
while Lines does. |
The lines provided by MS Word mean the actual lines shown on the
screen. It changes with display font sizes or page width, even if the text in
the file does not change at all. |
|
| Other differences |
Sometimes, STGuru and MS Word
provide different statistics for the "same" text. |
If you copy text from STGuru to MS Word
or vice versa, as the two text processor are of different internal
codes, copy+paste data from any one to the other may cause changes
to some character (such as double-byte to single byte, or single
byte to double byte, or some character cannot be recognized).
Usually, the changes are some unimportant minor changes.
As now there are small differences in the text, the
statistics cannot be the same.
If you copy+paste text from one to another, and
then from the other back to the original one, you will go over all
the changes, and there will be no further changes even if you
copy+paste text between the two text processors for more times. Now,
with the finally same text, STGuru and MS Word will provide the same
statistics. |
9.2 Character Occurrences
You can find this function from the Tools menu.
It can be used to find out all the Chinese and non-Chinese
characters appearing in a text together with the occurrences of each character
in this text. The data can be sorted naturally (by character values in the
Unicode Character set), or ascending or descending by occurrences.
It can be very helpful for professionals highly concerned about
linguistic quality of their documents. Usually no more than 4,000 different
Chinese characters are used in even a long Chinese document. If you sort the
result naturally, single-byte English digits, letters and punctuation marks will
appear first, then double-byte Chinese characters, including punctuation marks,
common Simplified Chinese characters and Traditional Chinese characters, and
uncommon characters, will be listed separately later. If your document is a pure
Chinese document and if there are "unwanted" single-byte English characters,
uncommon characters or unrecognizable characters in this document, you will
easily locate them in the result. If you sort the result by occurrences, you may
very possibly find, in the low-frequency section, some characters that you do
not expect in you document (such as typos). With the result at hand, you can
locate the real problems in the text by the full-text find (Find/Replace)
feature of STGuru or any other text processor and fix them accordingly.
This feature is designed for the text in the current edit area.
This means if the cursor is in the upper edit text, the result is for the text
in the upper edit area, and if the cursor is in the lower edit text, the result
is for the text in the lower edit area.
9.3 Text Difference Check
You can find this function from the Tools menu.
You
can check the differences between the upper and the lower edit areas. Line
numbers and contents of the different lines will appear in the check result.
While
using this command, the font and language for the two edit areas should be
set as the same. If you use a small font with a wide UI, it can be easy
for you to find different lines. If you narrow the UI, you can locate specific
places of difference easily.
9.4 Line Sorting
You can find this function from the Tools menu.
You
can use this command to sort lines in the upper or lower edit areas, or selected
text in the upper or lower edit areas, or text in the Clipboard in ascending or
descending order.
9.5 Redundant Line Management
You can find this function from the Tools menu.
This
command can be used to analyze or remove redundant lines.
Target:
upper or lower edit area, selected text in upper or lower edit area and text in
the clipboard.
Operation:
1. Analysis; 2. Removing redundant lines.
After
you have got the analysis result, you can click the button "Details"
to read content and extra line count for each group of redundant lines.
If
you choose to remove redundant lines, the first line of each group of redundant
lines will be remained, while all other extra lines will be deleted.
9.6 Chinese-English Glossary Management - Merge, Split, Swap...
You can find this function from the Tools menu.
This
command can help you organize Chinese-English glossary in different forms.
Target:
upper and lower edit areas, selected text in upper and lower edit areas, text in
the Clipboard.
Chinese
and English phrases before reorganization can be in any of the following forms:
1)
A phrase pair will appear in two lines - Chinese at first line, and English at
second, or English at first line, and Chinese below it.
2)
One phrase pair will be in one line, Chinese at left, English at right, or
English at left, and Chinese at right.
3)
Multiple pairs of Chinese and English phrases can be lined one pair next to another
continuously in the same line.
The
pair pattern after organization can also be in one of above forms. It's sure the
form before and after the organization can be different. For example, before
organization, the pair of Chinese and English phrases can in the same line one
next to another continuously. After the organization, they can be changed to
each phrase in a separate line. Another example, before organization, the Chinese and English
phrase can be in two lines, each one in a line, and after the organization, they can be organized
as each whole pair in a line.
The
default separators supported by the program are blank space, English comma,
English colon and English semicolon. If you prefer other separator, you can
realize it by replacing your separator to the standard separator before
organization, and change back after organization.
9.7 Chinese Characters to Decimal/Hexadecimal Unicode Codes
You can find this function from the Tools menu.
The feature was previously named Baidu Post Assistant, used to
post on Baidu Tieba in Traditional Chinese. Baidu canceled the mechanism later,
and the function by STGuru was also canceled. However, some users may still want
to convert Chinese characters from GBK/Big5/Unicode to Unicode in
decimal/hexadecimal codes for some other specific purposes, so we kept the module and renamed it to the current
one after necessary reform and improvements.
When using this feature, you can put Chinese
text in GBK or Big5 to the Source Text edit box for automatic conversion,
or use Unicode text you have copied to Windows clipboard as the source and then
convert it manually.
The resulting codes can be put into a Web page's code page, then the relevant
Chinese text will be displayed when this Web page is displayed. For example, the
decimal and hexadecimal codes converted from "街道" are "街道"
and "街道" respectively. After you post these codes to
the code page of a Web page, "街道" will be displayed in the
relevant position when this Web page is displayed.
Convert text in the "Source text" edit box
When you select the first three options - "GBK (converted
automatically)", "Big5 (converted automatically)"
or "Auto-Detect (converted automatically)", the text in the Source text edit box is used as
the source. The respective codes in the edit box for these three codes are GBK,
Big5 and what is detected by the software automatically. A good news is you can
visually edit the source text. Besides, the codes to
output are generated automatically in the code area below. After you have done
editing, you can click the Copy button below the codes edit box and paste
them to where you want to use.
Convert Unicode format text in
the clipboard
When you select the last option "Use Unicode-Format Text in
the Clipboard" in the source code drop-down list, the text in the clipboard
is used as the source, the format of which should be Unicode. If the system you
use is not the very ancient Windows 98/Me, but more common Windows 2000+
operating systems, when you copy text from Windows utilities such as Notepad,
from Microsoft Office or directly from a Web page, all the formats of text are
Unicode.
In this mode, you need to click the Convert button above
the code edit box manually to perform conversion.
When text in the "Source text" edit box is used as the source,
only characters in the GBK and Big5 character sets are supported. However, when
you use the Unicode format text in the clipboard as the source, you will have
the whole Unicode character set available to choose from.
"Decimal" and "Hexadecimal"
If you choose the "Decimal" option at the lower left, the output
codes will be 5-digit decimal numbers. If you choose "Hexadecimal", the codes
will be in 4-digit hexadecimal numbers.
9.8 Page Cleaning
Run
The function of Page Cleaning is attached as preinstalled macros in the Batch Replace dialog box. They can run in the following steps:
1) Open the Find/Replace dialog box for the upper area (by the
Find/Replace
menu item under the Edit menu for the upper area, or by the corresponding
button on the upper toolbar). This dialog box can be opened only when there is
text in the upper edit area. If there is no text in the upper area, you can
paste some text into it by yourself.
2) Click the Batch Replace button to
open the Batch Replace dialog box.
3) Click the Open button. A drop-down
path list will pop up. If you are using a newly installed MLEditor, there
will be 3 default page cleaning macros in this list - "page clean.txt" ("Page Cleaning"
- for English text), "page
clean-GBK.txt" ("Page Cleaning for GBK" - for Chinese in GBK) and "page clean-Big5.txt"
("Page
Cleaning for Big5" - for Traditional Chinese in Big5). You can select the one
that you need.
Function
"Page Cleaning" is designed for the cleaning
of English text, while the other two are for the cleaning and normalization of
Chinese text in GBK and Big5, especially for paragraphs of articles in full or
nearly full-Chinese. You are not suggested to use a
Chinese page cleaning macro on English text or text mixed with English and
Chinese. Professional advice from English and Chinese linguists was carefully
considered while these macros were created. Applying relevant page cleaning
macros on text in the three languages/codes with respective version can promptly
normalize and clean its punctuations, blank spaces and paragraph layout.
Custom page cleaners
If you have some special page cleaning requirements, you can
create your own page cleaning macro based on one of these standard page cleaning
macros.
You can make a new custom macro just by modifying the path and saving it. Then
you can modify the title, description and all items in this macro
according to your special requirements. After several rounds of tests and
revisions, you will get the finished macro.
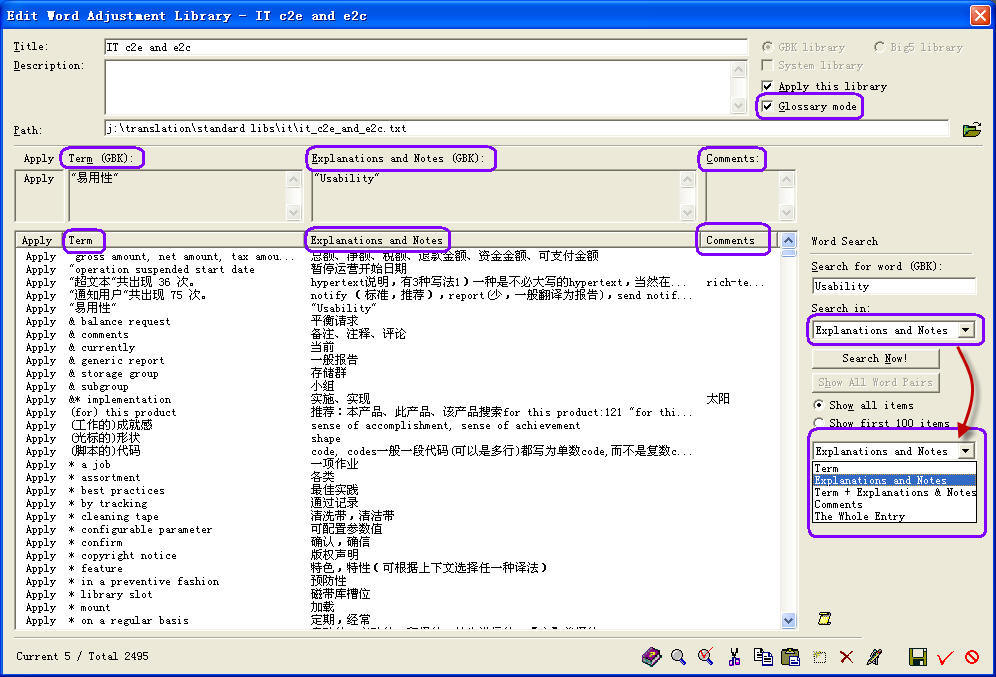
9.9 Term Management System
The word adjustment system (Conversions -> Advanced Word Adjustment)
itself is an advanced term management system by itself.
It manages terms in project packs. In each pack, you can manage one or
several libraries (glossaries). Each pack is self-contained and is comprised of
a simple text-based pack management file (.stcp file) and one or several plain-text library (glossary) files. Such a
project is portable, and can be easily shared whenever necessary. You can
double-click a .stcp file to open it from Windows Explorer, or can select it
from the pack list in the main interface of Advanced Word Adjustment.
You can conveniently add, modify, delete, find/search, cut, copy, paste entries.
While adding/editing entries, STGuru can check for repetitive entries
automatically, so you do not need to worry that you may add one term in a
library twice. Terms are automatically sorted in the library (glossary) after
they are added, so the source file for each library is a text file containing a
sorted glossary.
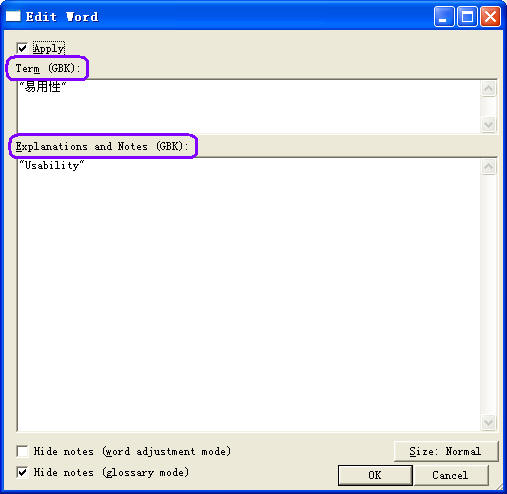
Each entry contains three parts - term, explanation and notes. The Edit Word
dialog box was specially optimized for editing entries in a glossary. Its
interface can be scaled. "Notes" can be shown or hidden. The smallest
interface shows only several lines, while the largest one can show up to 1000
Chinese characters or English words.
Glossaries can be easily merged (simply append the text of one source file at the end of another!). When you open a merged library in STGuru, the program will reorganize its entries automatically. If there are repeating entries, you will see a wizard that guides you through merging repeating entries one by one.
|